Introduction
The preview version of DeepSeek V4 has been released as open source, and the first wave of evaluations from third-party rankings has emerged. Various assessments indicate that DeepSeek V4 has made significant strides, particularly in coding tasks, positioning itself among the top open-source models while lowering the entry barrier for developers with its “million-level context + low price”.
Performance Evaluation
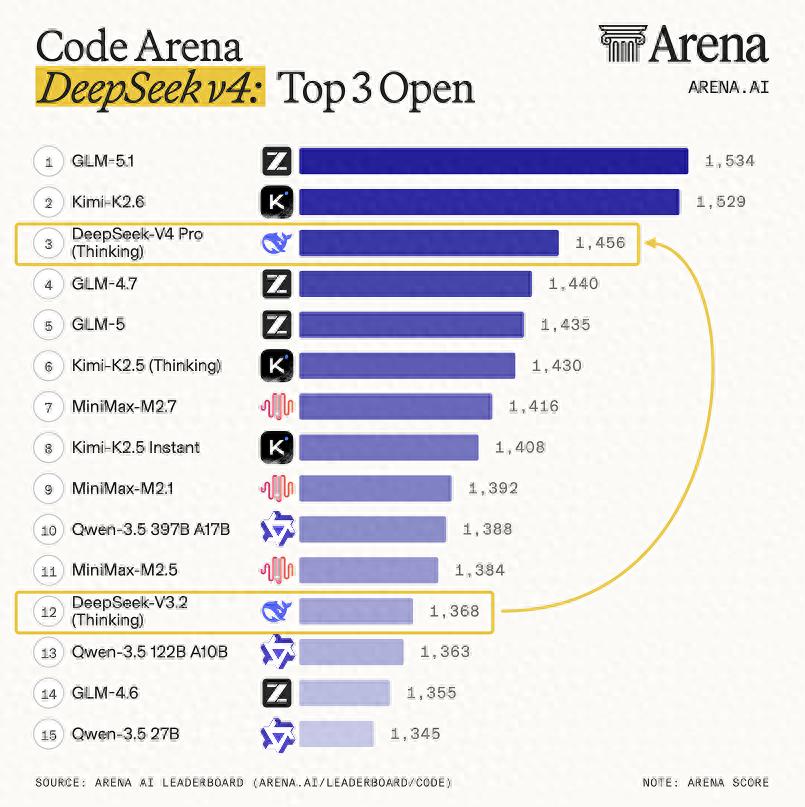
According to third-party evaluations, the testing platform Arena.ai has classified V4 Pro (thinking mode) as a “major leap compared to DeepSeek V3.2,” ranking it third among open-source models and fourteenth overall in its code arena. Another evaluation by Vals AI stated that V4 achieved the top spot in its Vibe Code Benchmark with an “overwhelming advantage,” outperforming closed-source models like Gemini 3.1 Pro and achieving approximately a tenfold performance increase over the previous version, V3.2.
In terms of pricing, V4-Flash’s output price is $0.28 per million tokens, over 99% lower than Claude Opus 4.7. V4-Pro’s output price is $3.48, making it one of the lowest-priced options among leading models. Comparison tables indicate that Flash is at the lower end of small models, while Pro is positioned low among large models.
Community Feedback
Discussions around the actual experience have begun to diverge. Many users on X have remarked on its cost-performance ratio being “off the charts.” However, DeepSeek’s own documentation maintains a cautious tone, stating that while it is close to closed-source systems in knowledge and reasoning, there remains a gap of about 3 to 6 months. It also noted that “due to high-end computing limitations,” Pro service throughput is limited, with expectations of price reductions in the future.
Third-Party Evaluation: Dominance in Coding Capabilities
Following the recent release of OpenAI GPT-5.5, the DeepSeek-V4 preview version has officially launched and is open-sourced, featuring the V4-Pro model with a total parameter count of 1.6 trillion (49B active parameters) and the V4-Flash model with 284 billion parameters (13B active parameters). Both models support a context window of 1 million tokens and are licensed under the MIT open-source protocol.

Arena.ai announced on the day of V4’s release that DeepSeek V4 Pro ranked third among open-source models in its code arena and fourteenth overall, marking a significant leap compared to DeepSeek V3.2. Arena.ai also tested V4 Flash, with both models supporting a 1 million token context.
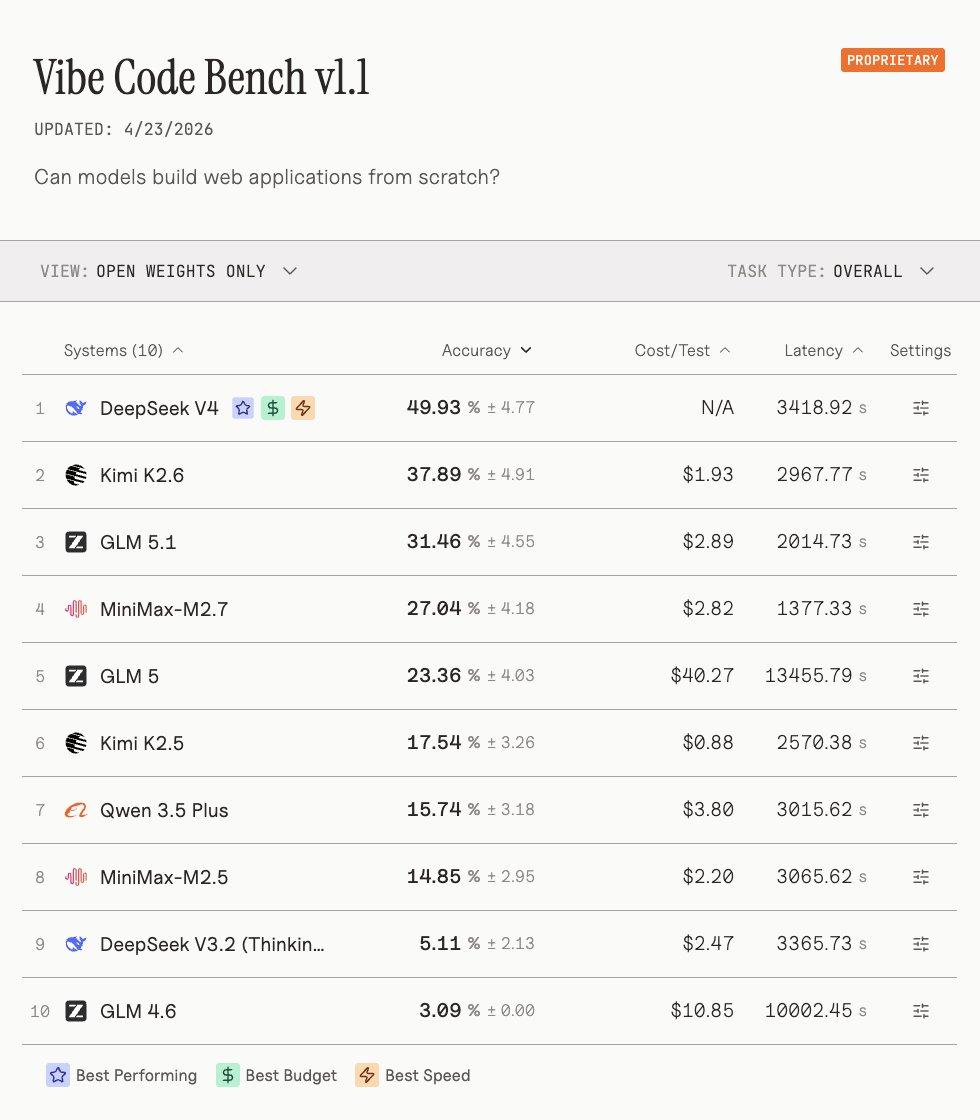
Vals AI’s evaluation results are particularly noteworthy, stating that DeepSeek V4 became the top open-source weight model in its Vibe Code Benchmark with an “overwhelming advantage,” surpassing the second-ranked Kimi K2.6 and defeating closed-source frontier models like Gemini 3.1 Pro.

Vals AI emphasized that V4 achieved approximately a tenfold performance increase over V3.2—“V3.2 scored only 5 points on this benchmark, and that is not a typo.” In Vals’ comprehensive index ranking, V4 finished in second place, just 0.07 points behind the leader Kimi K2.6.
Community reactions have been very positive. User Sigrid Jin on X remarked that it brought a new “shocking moment,” mentioning that “now you can run a model akin to GPT 5.4 at home.” He stated:
“GPT-5.5, sorry, DeepSeek V4 is the new shocking moment, it beat GPT-5.4 in high-intensity mode in the code arena.”
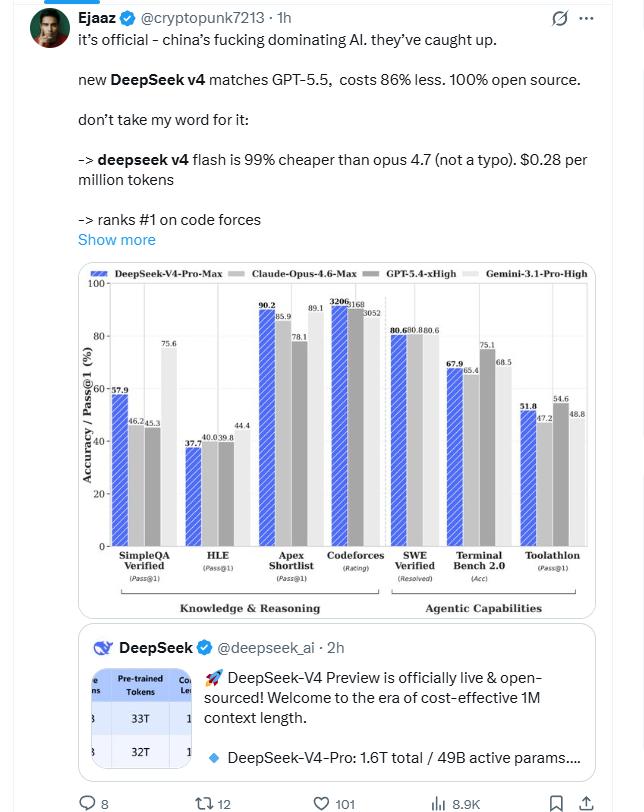
User Ejaaz commented:
“China is leading in AI; they have caught up. DeepSeek V4 Flash is 99% cheaper than Opus 4.7, costing only $0.28 per million tokens, ranking first in the code arena, and this is not a typo.”
However, some users expressed reservations. User Michael Anti on X stated that after trying it, the actual experience of V4 Flash did not surpass the already mature V3.2, finding the upgrade experience disappointing for long-time users.
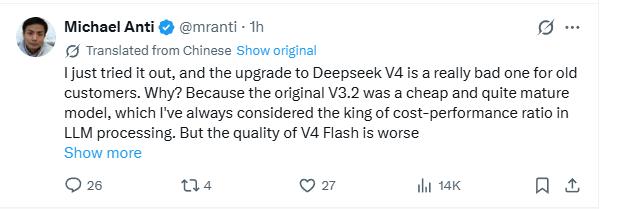
Official Self-Assessment
DeepSeek maintains a consistent cautious tone in its self-assessment of performance. Official documents indicate that V4-Pro has surpassed mainstream open-source models in knowledge and reasoning tasks, approaching closed-source systems like Gemini, but still lags behind the most advanced frontier models by about 3 to 6 months. In the Agent and coding tasks, its performance is close to or even exceeds Claude Sonnet.
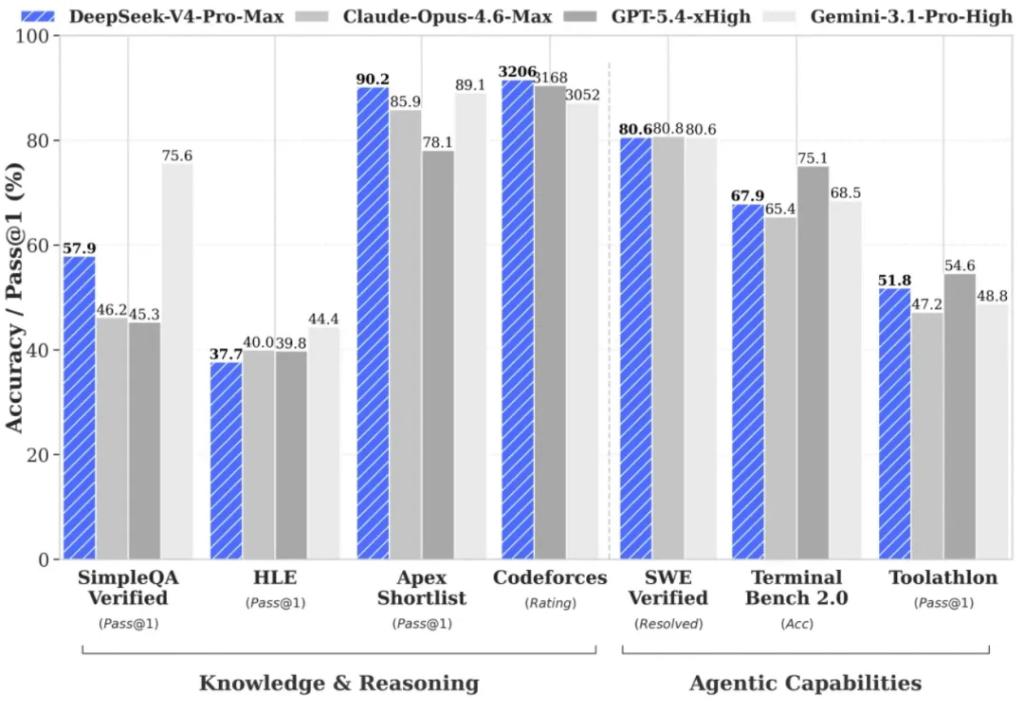
Regarding internal usage data, DeepSeek states that V4 has become the primary model for Agentic Coding among company employees, with feedback indicating that its user experience surpasses Claude Sonnet 4.5, and the delivery quality is close to Opus 4.6 in non-thinking mode, but still has some gaps compared to Opus 4.6 in thinking mode.
In mathematical, STEM, and competition-level code evaluations, V4-Pro has surpassed all currently publicly evaluated open-source models, including Kimi K2.6 Thinking and GLM-5.1 Thinking, achieving results comparable to top closed-source models.
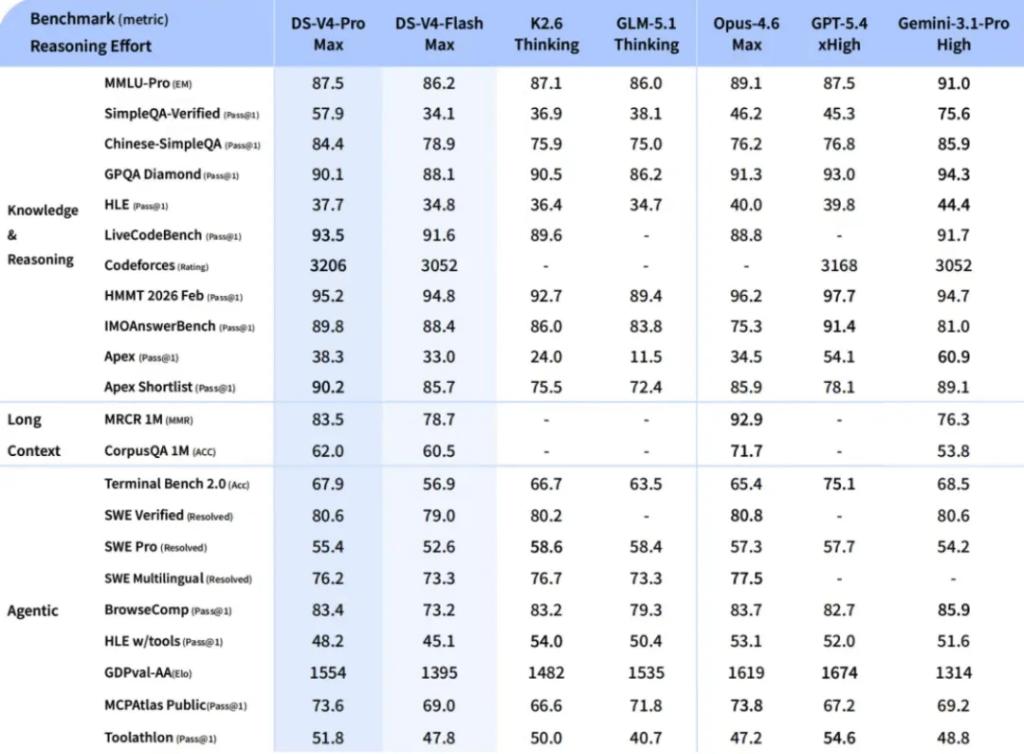
Blogger Simon Willison pointed out in his review that V4-Pro (1.6 trillion parameters) is currently the largest known open-source weight model, surpassing Kimi K2.6 (1.1 trillion), GLM-5.1 (754 billion), and DeepSeek V3.2 (685 billion), providing new options for enterprise users interested in local deployment.
He also shared the pelican diagrams produced by different models:
Here is the pelican from DeepSeek-V4-Flash:
As for DeepSeek-V4-Pro:


Pricing Structure
DeepSeek’s pricing strategy has garnered significant market attention during this release. V4-Flash’s input/output prices are $0.14/$0.28 per million tokens, lower than OpenAI GPT-5.4 Nano ($0.20/$1.25) and Gemini 3.1 Flash-Lite ($0.25/$1.50), making it the lowest-priced option among small models.
V4-Pro’s input/output prices are $1.74/$3.48, also lower than Gemini 3.1 Pro ($2/$12), GPT-5.4 ($2.50/$15), Claude Sonnet 4.6 ($3/$15), and Claude Opus 4.7 ($5/$25).
Blogger Simon Willison’s compiled price comparison data shows that V4-Pro is currently the lowest-cost option among large frontier models, while V4-Flash is the lowest-cost among small models, even cheaper than OpenAI’s GPT-5.4 Nano.
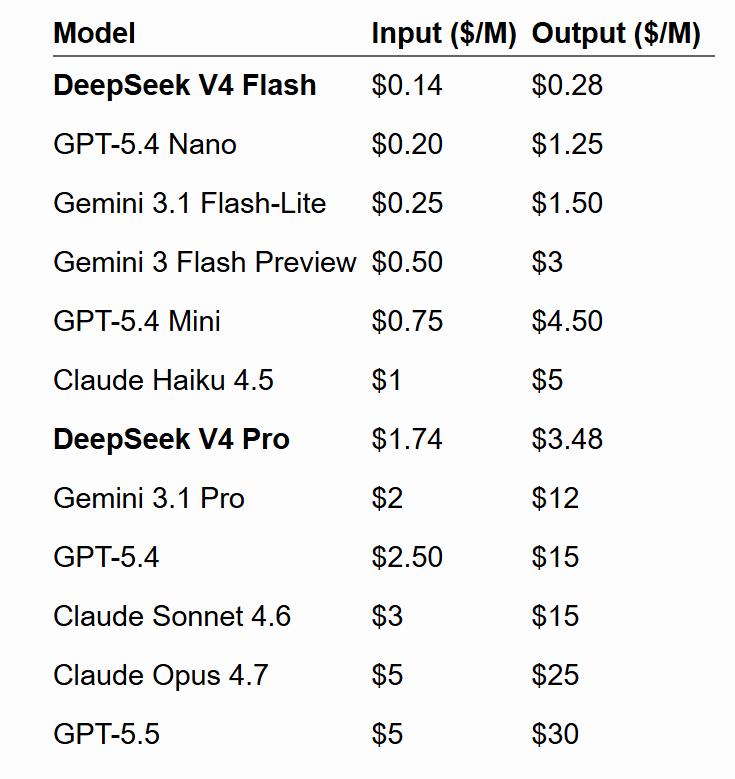
DeepSeek attributes its low-price capability to the extreme efficiency optimization of the model in ultra-long context scenarios. Official data indicates that under the 1 million token scenario, V4-Pro’s single-token inference computing power is only 27% of that of V3.2, and KV caching is only 10%; V4-Flash is even lower at 10% and 7% respectively.
It is noteworthy that DeepSeek mentioned in its pricing explanation that “due to high-end computing limitations, the current throughput of Pro services is very limited, and it is expected that prices will be significantly reduced after the large-scale launch of Ascend 950 super nodes in the second half of the year,” suggesting that the current pricing still has room for further reductions.
Technical Architecture
The core technological innovation of DeepSeek-V4 lies in its pioneering “CSA (Compressed Sparse Attention) + HCA (Heavy Compressed Attention)” hybrid attention architecture, aimed at addressing the industry pain points of traditional attention mechanisms that exhibit quadratic complexity in ultra-long context scenarios, making it challenging to engineer memory and computing resources. CSA compresses every four tokens into one information block and retrieves the most relevant content through sparse search, significantly reducing computational load while retaining mid-segment details; HCA condenses massive information into framework-level information blocks, focusing on global logical processing.
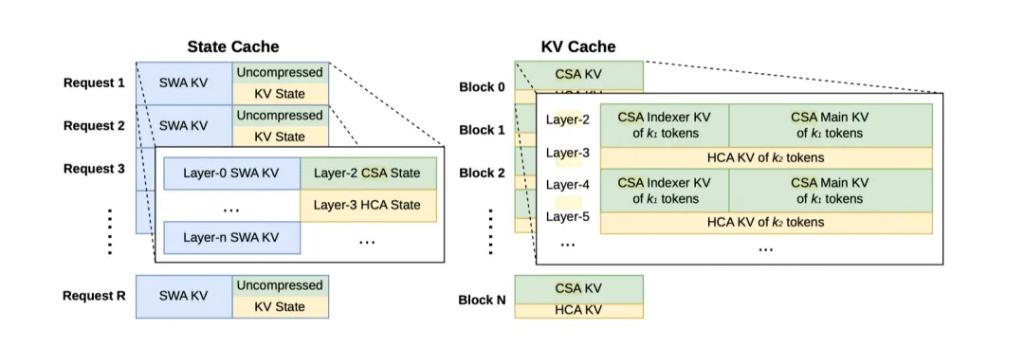
Additionally, V4 introduces mHC manifold constraint superconnections (upgrading traditional residual connections to constrain signal propagation on stable manifolds) and the Muon optimizer (replacing the traditional AdamW, adapting to MoE large models and low-precision training). Official data shows that full-link engineering optimization can achieve inference acceleration of nearly 2 times.
In terms of adaptation to domestic computing power, DeepSeek-V4 has completed comprehensive verification of fine-grained expert parallel optimization schemes on the Huawei Ascend NPU platform, achieving an acceleration ratio of 1.50 to 1.73 in general inference load scenarios. DeepSeek officially states that V4 is the world’s first trillion-parameter model trained and inferred on a domestic computing foundation, but the Ascend platform adaptation code has not yet been open-sourced, remaining a closed-source optimization. Additionally, Cambricon has completed the adaptation of V4-Flash and V4-Pro through the vLLM inference framework, with related code open-sourced to the GitHub community.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.